E(e): It maps to RTF_EXPIRES. It means the route has a non-infinite lifetime. In this case, the kernel probably learned the route dynamically from a RA (Router Advertisement).
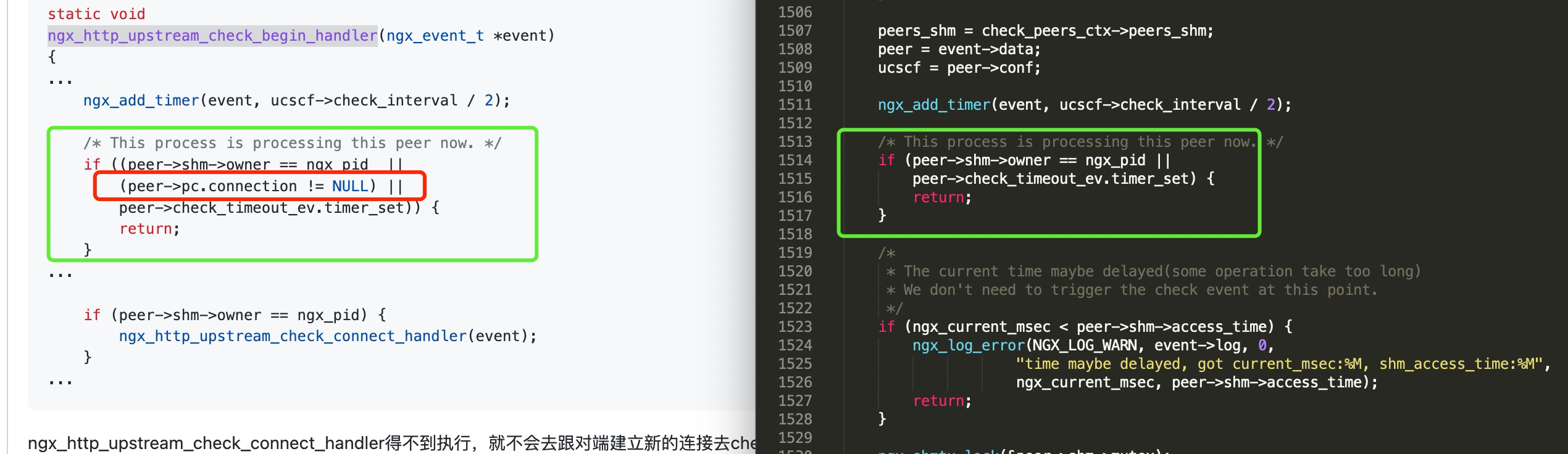
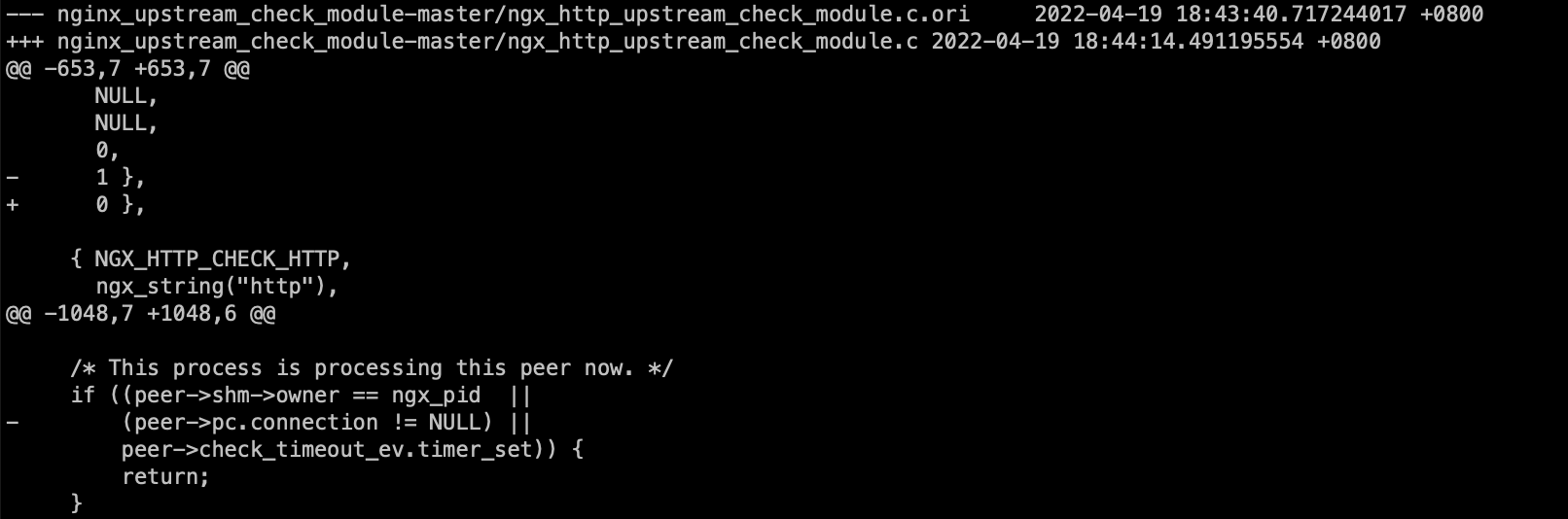
这个路由其实是动态广播的, 那么这个现象就跟一个参数有关了
net.ipv6.conf.interface.accept_ra
Accept Router Advertisements; autoconfigure using them.
It also determines whether or not to transmit Router Solicitations. If and only if the functional setting is to accept Router Advertisements, Router Solicitations will be transmitted.
Possible values are: 0 Do not accept Router Advertisements. 1 Accept Router Advertisements if forwarding is disabled. 2 Overrule forwarding behaviour. Accept Router Advertisements even if forwarding is enabled.
Functional default: enabled if local forwarding is disabled. disabled if local forwarding is enabled.
Nb: per interface setting (where “interface” is the name of your network interface); “all” is a special interface: changes the settings for all interfaces
默认系统这个参数是1, 当开启forwarding的时候, 不接受路由广播, 所以这个场合, 应该修改为2, Accept Router Advertisements even if forwarding is enabled.
UP U
GATEWAY G
REJECT !
HOST H
REINSTATE R
DYNAMIC D
MODIFIED M
DEFAULT d
ALLONLINK a
ADDRCONF c
NONEXTHOP o
EXPIRES e
CACHE c
FLOW f
POLICY p
LOCAL l
MTU u
WINDOW w
IRTT i
NOTCACHED n
ping 10.4.224.100 -I tunnelX PING 10.4.224.100 (10.4.224.100) from 172.16.172.1 tunnelX: 56(84) bytes of data. ^C --- 10.4.224.100 ping statistics --- 77 packets transmitted, 0 received, 100% packet loss, time 77858ms
查看本地linux的日志可以看到数据包被drop了
Mar 18 09:37:25 gw kernel: IPv4: martian source 10.4.224.100 from 172.16.172.1, on dev tunnelX Mar 18 09:37:25 gw kernel: IPv4: martian source 10.4.224.100 from 172.16.172.1, on dev tunnelX
由于是reverse path 校验嘛, 给它加个路由
ip route add 172.16.0.0/16 dev tunnelX table myRouteTable
于是, 通了
ping 10.4.224.100 -I tunnelX PING 10.4.224.100 (10.4.224.100) from 172.16.172.1 tunnelX: 56(84) bytes of data. 64 bytes from 10.4.224.100: icmp_seq=1 ttl=62 time=2.22 ms 64 bytes from 10.4.224.100: icmp_seq=2 ttl=62 time=37.9 ms
1 - Strict mode as defined in RFC3704 Strict Reverse Path Each incoming packet is tested against the FIB and if the interface is not the best reverse path the packet check will fail. By default failed packets are discarded.
严格检测模式
2 - Loose mode as defined in RFC3704 Loose Reverse Path Each incoming packet's source address is also tested against the FIB and if the source address is not reachable via any interface the packet check will fail.
松散检测模式, 只要有一个设备接口有这个地址就可以
Current recommended practice in RFC3704 is to enable strict mode to prevent IP spoofing from DDos attacks. If using asymmetric routing or other complicated routing, then loose mode is recommended. The max value from conf/{all,interface}/rp_filter is used when doing source validation on the {interface}. Default value is 0. Note that some distributions enable it in startup scripts.
一些旧设备访问nginx的时候可能会出现400 bad request, 这个跟2020.2月nginx移除了一个兼容特性有关
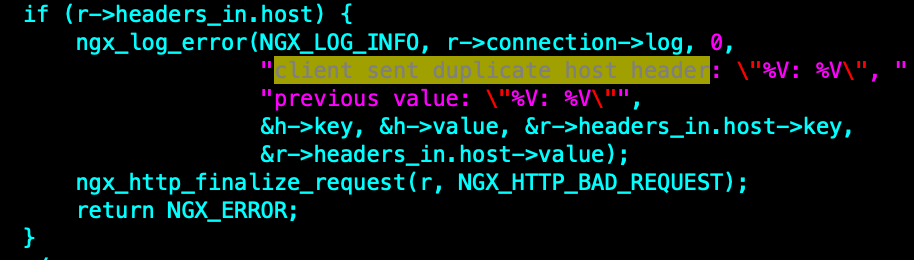
Disabled duplicate “Host” headers (ticket #1724). Duplicate “Host” headers were allowed in nginx 0.7.0 (revision b9de93d804ea) as a workaround for some broken Motorola phones which used to generate requests with two “Host” headers[1]. It is believed that this workaround is no longer relevant.
新增的这块代码如下: 会判断是否有重复的host 头, 而在之前的版本是认为可以容忍的
这个兼容特性被移除后, 会导致一些旧版本的移动设备响应异常
而我们线上测试机器主要是兼容了spdy协议, 也出现了400 BAD REQUEST, 这个跟spdy代码里边本身进行了一遍header处理有关: