cd nginx-1.25.0
./configure
--with-debug
--with-http_v3_module
--with-cc-opt="-I../boringssl/include"
--with-ld-opt="-L../boringssl/build/ssl
-L../boringssl/build/crypto"
make && make install
http {
log_format quic '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" "$http3"';
access_log logs/access.log quic;
server {
# for better compatibility it's recommended
# to use the same port for quic and https
listen 443 quic reuseport;
listen 443 ssl http2 reuseport backlog=8192;;
ssl_certificate certs/example.com.crt;
ssl_certificate_key certs/example.com.key;
location / {
# required for browsers to direct them to quic port
add_header Alt-Svc 'h3=":443"; ma=86400';
}
}
}
一些旧设备访问nginx的时候可能会出现400 bad request, 这个跟2020.2月nginx移除了一个兼容特性有关
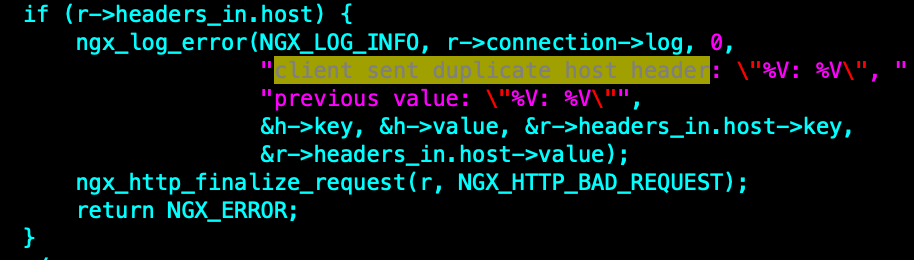
Disabled duplicate “Host” headers (ticket #1724). Duplicate “Host” headers were allowed in nginx 0.7.0 (revision b9de93d804ea) as a workaround for some broken Motorola phones which used to generate requests with two “Host” headers[1]. It is believed that this workaround is no longer relevant.
新增的这块代码如下: 会判断是否有重复的host 头, 而在之前的版本是认为可以容忍的
这个兼容特性被移除后, 会导致一些旧版本的移动设备响应异常
而我们线上测试机器主要是兼容了spdy协议, 也出现了400 BAD REQUEST, 这个跟spdy代码里边本身进行了一遍header处理有关:
# Make sure you are in 'src'.
# This part should only need to be done once, but it won't hurt to repeat it. The first
# time checking out branches and tags might take a while because it fetches an extra
# 1/2 GB or so of branch commits.
gclient sync --with_branch_heads --with_tags
# You may have to explicitly 'git fetch origin' to pull branch-heads/
git fetch
# Checkout the branch 'src' tree.
git checkout -b branch_$BRANCH tags/$BRANCH
# Checkout all the submodules at their branch DEPS revisions.
gclient sync --with_branch_heads --with_tags