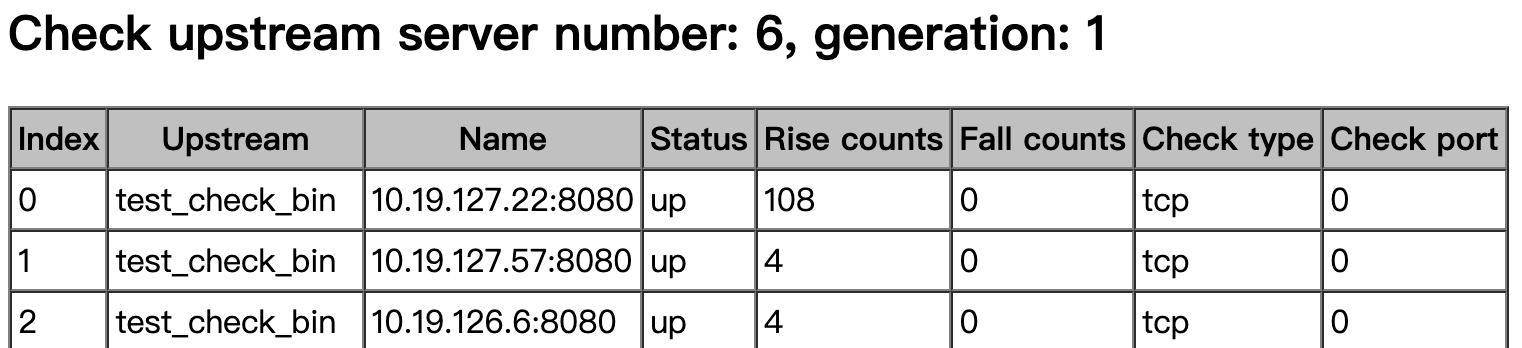
upstream test_check_bin {
server 10.19.127.22:8080;
server 10.19.127.57:8080;
server 10.19.126.6:8080;
keepalive 32;
check interval=10000 rise=2 fall=3 timeout=3000 default_down=false;
}
我们使用的是一个臭名昭著的模块 , 这个模块的作者去了淘宝后便只有tengine里边的模块得到更新了
https://github.com/yaoweibin/nginx_upstream_check_module
目前发现了在当前代码存在两个问题:
- TCP检查在几种情况下会失效, 比如交换机挂掉, upstream机器网线被拔了, upstream机器crash了
- TCP检查的rise count 存在不增加的情况, 主要是裸JAVA和JAVA容器(java -Dspring.profiles.active=local -jar httpbin-gateway-test.jar),裸python -m SimpleHTTPServer 80之类
第一个问题是因为这个版本的upstream check TCP代码使用的keepalive模式, 根据这个文章的解释TCP Keepalive的心跳包是7200s,两个小时,一旦建立,没有收到主动关闭请求的话在探测端会一直保留establish的状态

https://m.haicoder.net/note/tcpip-interview/tcpip-interview-tcp-keepalive.html
当upstream端突然硬件故障/交换机挂掉/网卡被拔之类的极端情况出现的 时候, nginx 基于keepalivedTCP检测是没办法捕获到这个情况的(检测模块没收到RST/或者dst unr包)
在正常情况下, 比如upstream 端web服务器 STOP了, web服务器oom被系统kill了, docker 实例被stop/kill了, 都会触发关闭连接的请求包 给到nginx 端, 能识别到服务down了


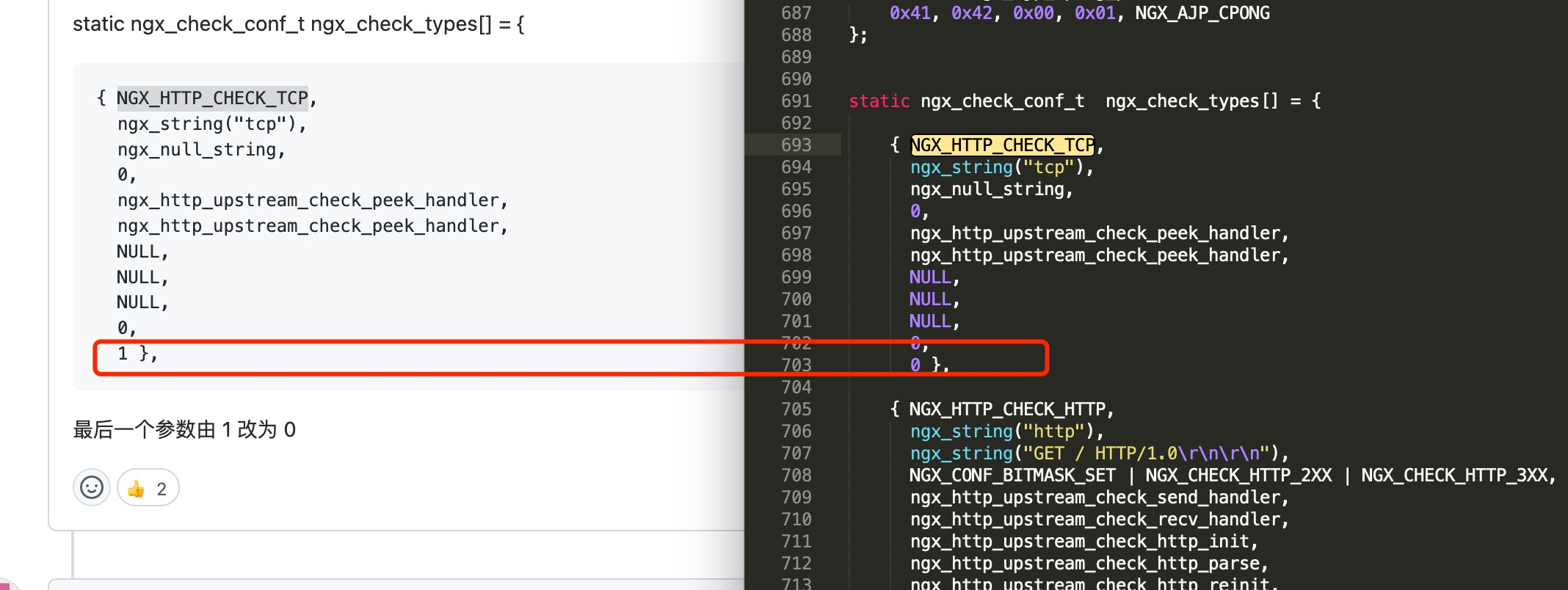
从tengine这个模块的最新代码看, 作者也意识到了这个问题, TCP检测把need_keepalive参数从1改成了0
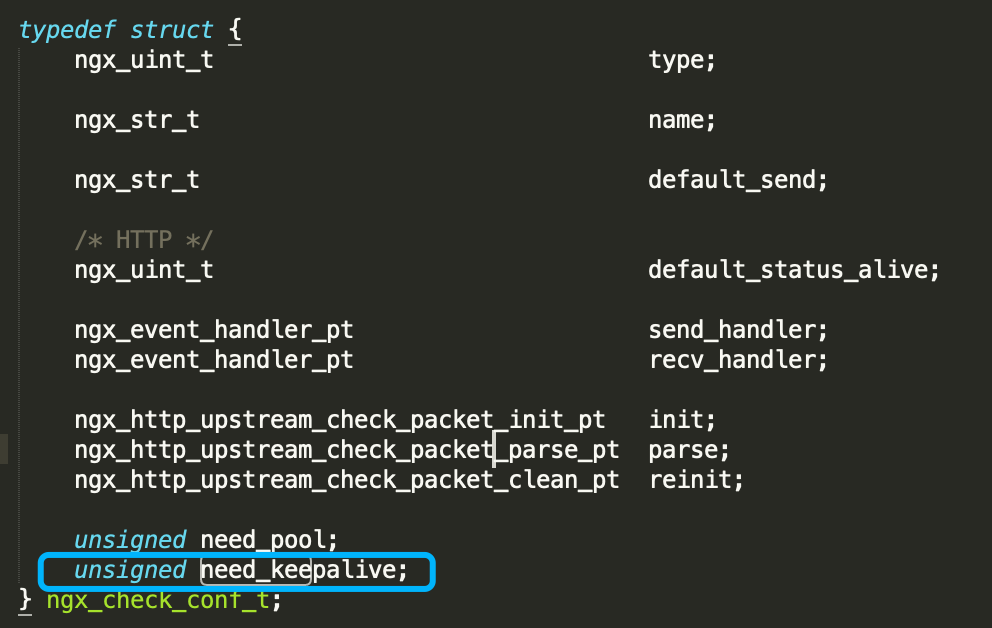
这个参数变成0之后会影响clean_event的操作, 每次检测完毕后会close掉连接,每个检测周期都会重新发起TCP连接

第二个问题: rise counts 不增加, 这个通常都是upstream 端listen 模式有问题导致, 它并没有正确的定期回包, 通常情况下, nginx, apache都能正常的主动回包让rise counts增加
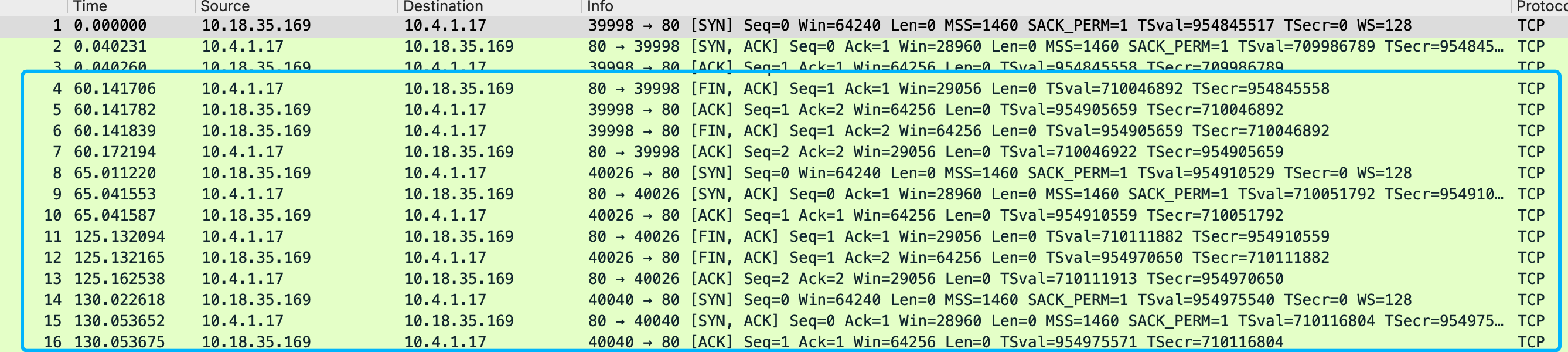
python java这些裸起的一些简单服务就没有定期主动回包, 而在这个版本的代码中, 会判断这个connection是否存在, 如果存在则return了导致计数器不会增加
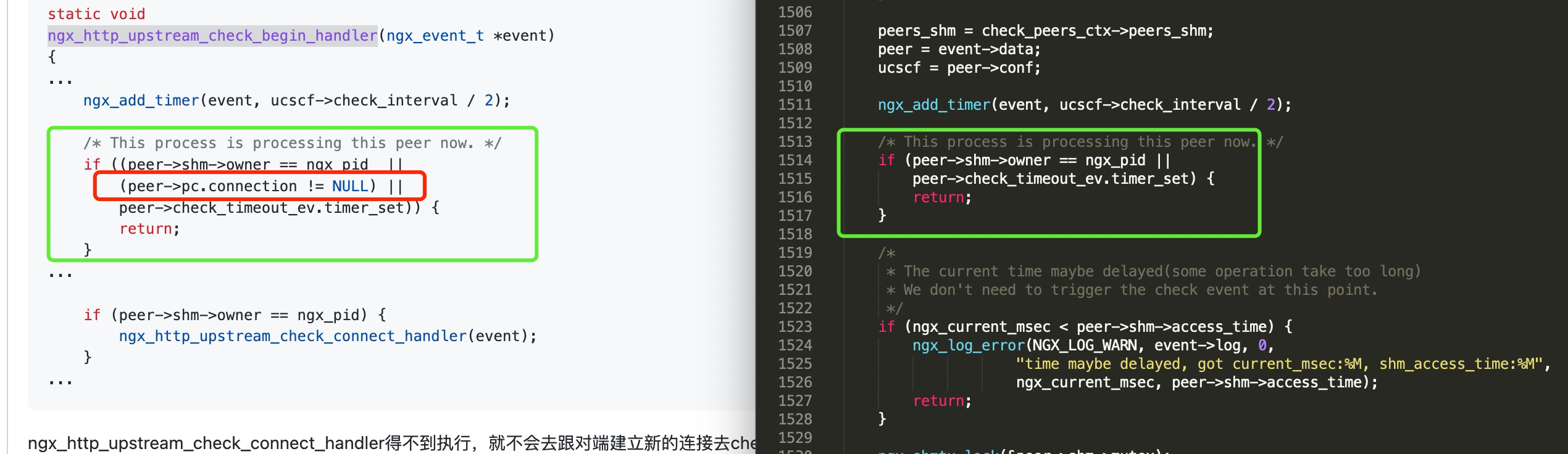
不过, 划重点: 无论是否回包, rise counts 是否增加,并不影响TCP监测的存活性, TCP监测keepalive模式仅仅以能否建立连接(刚启动时)/是否收到upstream的异常包为判断依据
总结: 为了避免过于复杂的处理逻辑, tengine去掉了keepalive的TCP探测,每次请求完都销毁连接,下次探测再重新协商请求
这里给下针对这个问题的patch:
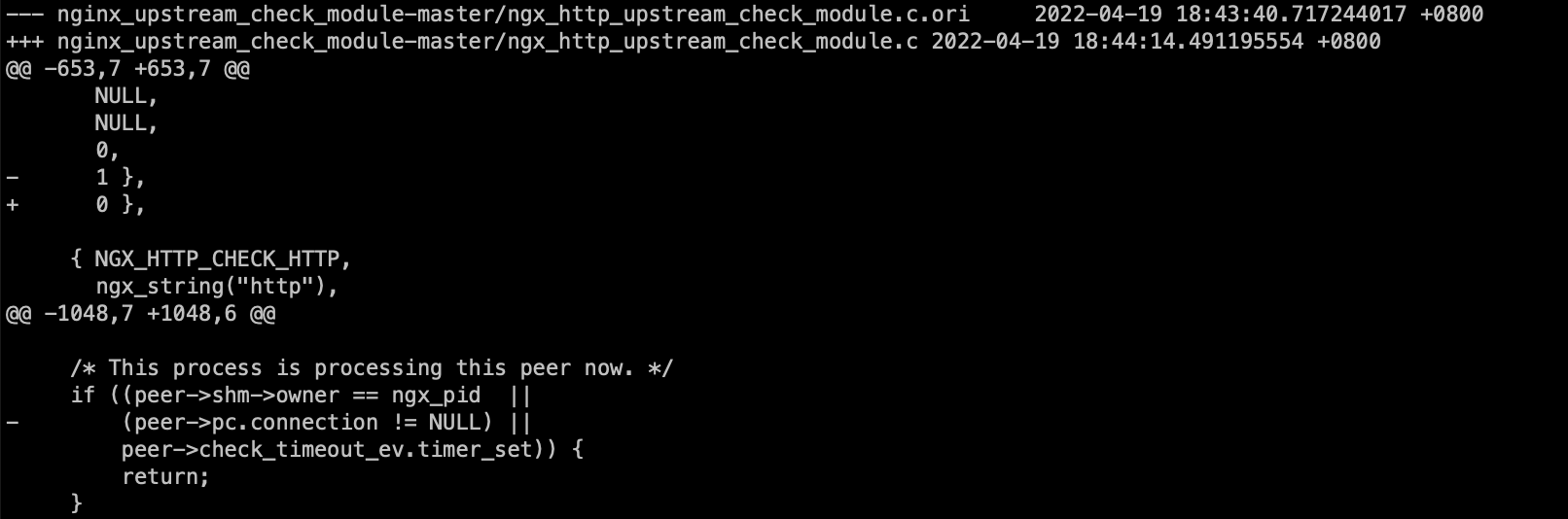
https://www.4os.org/patch/nginx_upstream_check_tcp.patch